Kārakā’s: Why Sanskrit is the perfect language for modern computing
A lot of you might have heard the statement – Sanskrit is the perfect language for modern computing . But why is this so? What makes Sanskrit so special? I hope to throw a bit of light on this over in today’s post.
For a computer to process a sentence correctly, it is important that every word in the sentence corresponds to a syntax which the computer can then interpret unambiguously. But language, when spoken by people for human communication hardly ever conforms to a clear and unambiguous syntax. Infact this had been one of the main hurdles to overcome in natural language processing and translation utilities
Lets look at an example of the ambiguity in the natural language by taking an English sentence
Rām is eating a fruit.
In English the order of the words matter a lot.
The order of the words (Rām), (Is Eating), (A fruit) determines our understanding on what will be the subject and object for that Verb. As you all know, over here Rām is the subject and a fruit is the object.
Now if we jumble up the words in English we get a completely different meaning.
A fruit is eating Rām. This sentence is grammatically correct, but we know it to be wrong unless it’s somehow a cannibalistic fruit 
We could make it worse and rearrange the articles around the sentence.
Fruit Rām eating is a. This is an absolutely nonsensical sentence construct, made even more so because the articles are in the wrong place.
Now Take the same sentence in Sanskrit
Rāmah (Rām) Phalam (a fruit) Khadati (is eating) / रामः फलम् खादति
If I were to reorder the Sanskrit words then I would end up forming any of the following sentences.
Khadati Rāmah Phalam / खादति रामः फलम्
Phalam Khadati Rāmah / फलम् खादति रामः
Phalam Rāmah Khadati / फलम् रामः खादति
The beauty of Sanskrit is that irrespective of the order in which you rearrange the words, we still end up with a sentence that has its meaning intact and is also grammatically correct. This is because each word in Sanskrit carries a lot of information about the word. To understand this better we need to look at the basic components of a sentence or Vākya (वाक्य) .
Essentially a sentence is a combination of words that describes some action. In Sanskrit at the core of the sentence is the main action or kriyāpada (क्रियापद). All other words in the sentence are just enhancing the information around the action and they are called nāmapadas (नामपद) and provide information around the main action.
According to the Kāraka (कारक) concept in Sanskrit grammar, there are 6 main pieces of information about an action that we require in order to understand a sentence better.
1. Who performed the action or the kartā (कर्ता)? We call this the subject of the sentence in English
2. Who was affected by the action or the karma (कर्म) ? We call this the object of the sentence in English
3. What are the instruments associated with the action or the kāranam (कारणम्)?
4. For whom or what purpose was the action done or the sampradānam (संप्रदानम्)?
5. Where did the action originate/ separate from or the apādānam (अपादानम्)?
6. When and Where did the action occur (i.e The locus of the action) or the adhikaranam (अधिकरणम्)?
Lets look at a few examples to understand these 6 cases better.
1. Rāmah Khādati रामः खादति (Rām is eating). The action here is eating and Rām is the subject.
2. Vyāgrah Rāmam Khādati व्याग्रः रामम् खादति (The tiger is eating Rām). The action here is eating again, but this time Rām is being eaten and is the object. Notice how the ending of the word Rām changes
3. Lakshmanah Rāmena Saha Khādati लक्ष्मणः रामेण सह खादति (Lakshmana is eating along with Rām). The action again here is eating but the main subject is Lakshmana. Rām is instrumental in the action of Lakshmana’s eating, again, the form that Rām takes changes.
4. Sitā Rāmāya Dadāti सीता रामाय ददाति (Sitā gives to Ram). Here Sitā is the doner and Rām is the receiver and giving is the action. The purpose of the action is associated with Rām.
5. Rāvanah Rāmāt Dhāvati रावणः रामात् धावति (Rāvana runs away from Rām). Here the action is running, but Rāvan is doing the running and he is doing it away from Rām.
6. Dayā Rāme Asti दया रामे अस्ति (Compassion exists inside Rām). Here the verb is to exist, the subject is compassion or Dayā. Rām is the place (maybe his heart) where the compassion exists.
We also have the sentence Sitā Rāmasya Bhāryā Asti सीता रामस्य भार्या अस्ति (Sitā is Rām’s Wife). Here Rām is not really associated with the verb asti/ is, however there is a relationship or sambandhah (संबन्धः) between Rām and Sitā who is the subject of the sentence.
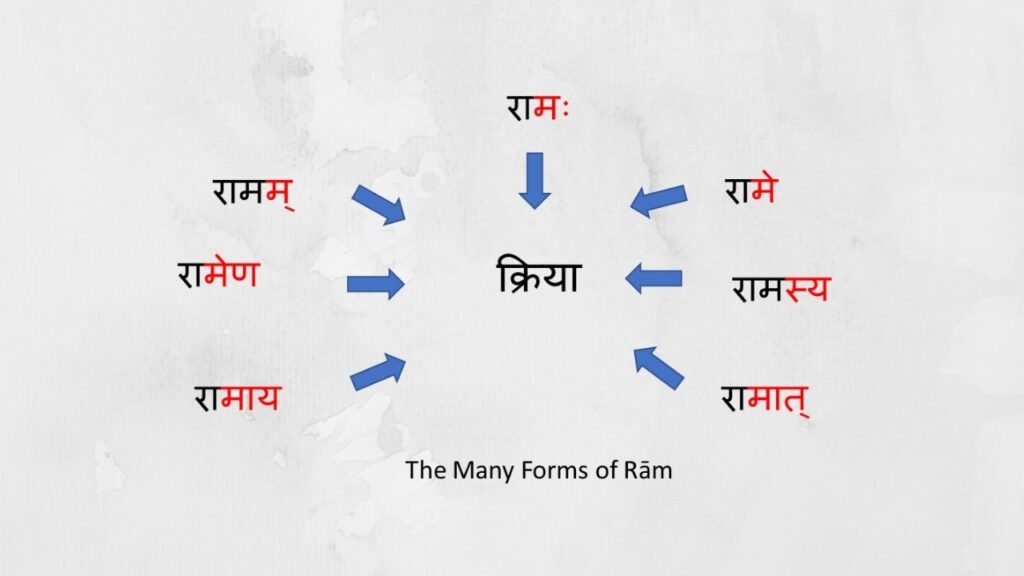
Even though in English the word Rām remained the same, in Sanskrit the word Rām itself undergoes modifications
Rāmah (Rām as a subject), Rāmam (Rām as an object), Rāmena (with Rām), Rāmaaya (for Rām), Rāmaat (From Rām), Rāme (inside Rām), Rāmasya (Belonging to Rām)
The word Rām morphs depending on the context of its relationship to the main verb in the sentence and it is this change to the word that tells us loads about the context of Rām in the sentence. In this manner every word in a sentence has a morphological structure that can help clarify its context in the sentence. And every word in the sentence is clear and unambiguous. Because of this property even we move words around in a sentence, the overall meaning of the sentence is unimpacted as the word retains its context due to its morphological structure. Infact most Indian languages follow a similar pattern although not as well structured and defined as in Sanskrit.
If you made it this far in the article, you might now be thinking, “All of this is mildly interesting. But how useful is it?”
For starters this property has provided amazing dexterity to the Sanskrit language allowing poets to play with each syllable in every word to make it more lyrical and rythmic, a necessity while composing slokas . It also allows for a lot of creative compositions. For example Rāghava Yādaviyam is a poem which when read from left to right tells the story of Rāma (or Rāghava) and when read in the reverse order from right to left tells the story of Yādava (Krishna). Just imagine trying to do this in English!! Not many have lived to tell such tales.
But even more importantly, in today’s world this feature of non ambiguity of words in the Sanskrit sentence has made it perfect for Natural Language Processing. The Sanskrit Kārakā based sentence syntax is the easiest to process compared to all other natural languages and can be the basis for a lot of language parsing tools and models for natural language processing . Infact a significant part of modern computational linguistics has a strong resemblance with the Kārakā concept of Sanskrit. Hopefully that is a strong enough reason for today’s technologist’s to study the language deeper!!

